随着自媒体和电商的蓬勃发展,AI技术正成为内容创作和营销的新宠。最近,我身边一位做自媒体的朋友为了推广店铺,接触到了一家新媒体公司。这家公司推出了一款小程序,宣称只需上传一段真人朗读数字(如“12345…”)的视频,就能根据文案生成AI克隆声音并实现唇形同步的视频。听起来是不是很酷?当你还在一天只能做两三条视频的时候,别人已经完成了大批量几十条的制作。然而,当我听说这项服务的价格——三个月使用权要2000元时,我不禁怀疑:这真的值吗?今天,我将带你深入了解AI数字人/唇形同步技术的原理与实现方式,并分享一套低成本、高质量的替代方案,让你不再被高价项目“割韭菜”。
一、唇形同步技术的现状:技术虽强,细节待完善
唇形同步技术,简单来说,就是让视频中人物的嘴型与音频内容精准匹配。在AI领域,这项技术已经取得了显著进展,其中 LatentSync 是目前最受关注的项目之一。早期的 LatentSync 以其出色的英文唇形同步效果著称,但中文支持却一直是短板,生成的嘴型常常对不上音频,让人一看就觉得“假”。
好消息是,2025年3月14日,LatentSync 发布了 1.5 版本,带来了三项重大升级:
- 时间一致性提升:通过新增时间层,生成的视频更加流畅自然。
- 中文性能优化:加入了中文训练数据集,嘴型匹配度显著提高。
- 硬件需求降低:第二阶段训练的显存需求从高不可攀降至 20GB。
我在实际测试中发现,LatentSync 1.5 的中文效果确实有了质的飞跃。然而,它仍有一个明显的不足:训练数据集的分辨率只有 256×256,导致生成的视频在嘴巴周围显得模糊,细节不够清晰。好在,这可以通过超分模型来解决——对生成的视频进行脸部高清增强处理后,效果甚至超过了市面上动辄数千元的小程序,比如“云生数智”这个小程序,可以了解一下,这是反面教材,不要去给别人送钱。看过我的文章你就可以用自己的电脑显卡跑,不用去缴智商税。
二、唇形同步视频的三大步骤
你是否也有一段真人朗读数字的视频和一篇推广文案,想让视频中的人物“开口”说出文案内容,同时嘴型同步、口齿清晰?别急,我将手把手教你如何用免费或低成本的工具实现这一效果,整个过程分为三步:
第一步:语音克隆
工具:CosyVoice2 一键包
获取方式:公众号,回复“Cosy”即可下载。
素材准备:
- 一段 3~15 秒的 MP3 音频,用于克隆视频中人物的音色(随便朗读一段文字即可)也就是下面图片中序号③的内容,不需要和视频文案内容一样,可以重复使用的。
- 这段 MP3 音频对应的文本内容。
- 你的视频文案(也就是你希望人物“说”出来的内容)。
操作流程:
- 下载并打开 CosyVoice2 一键包,点击一键启动程序。
- 上传准备好的 MP3 音频和对应文本,程序会分析音色。
- 输入你的视频文案,点击生成。

- 处理完成后,在 outputs 文件夹中找到克隆后的音频文件。
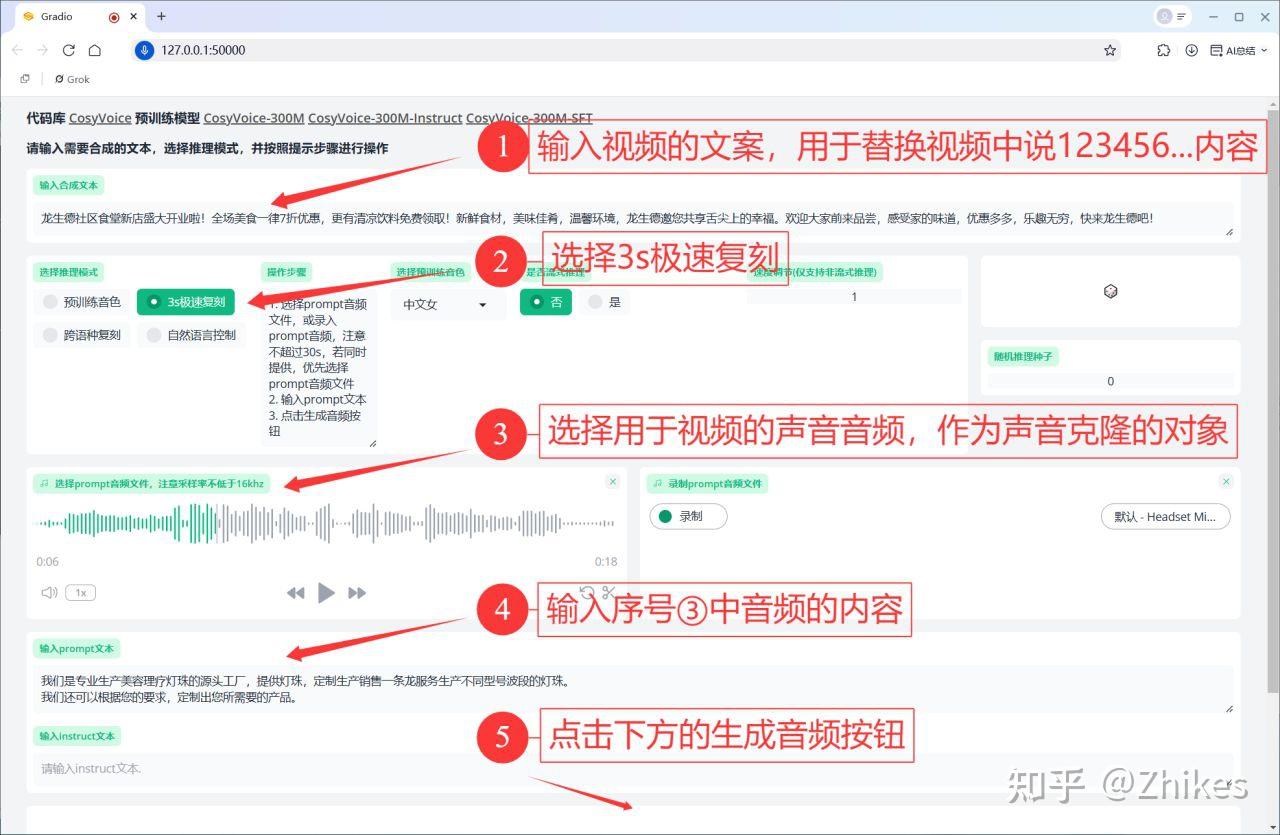
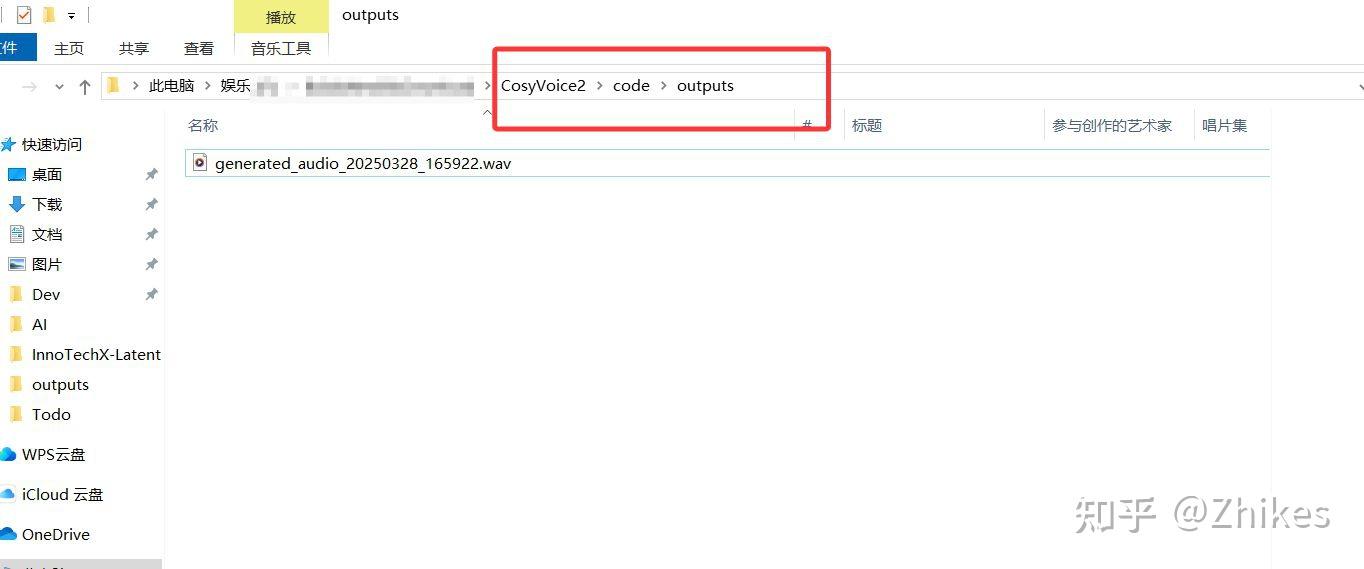
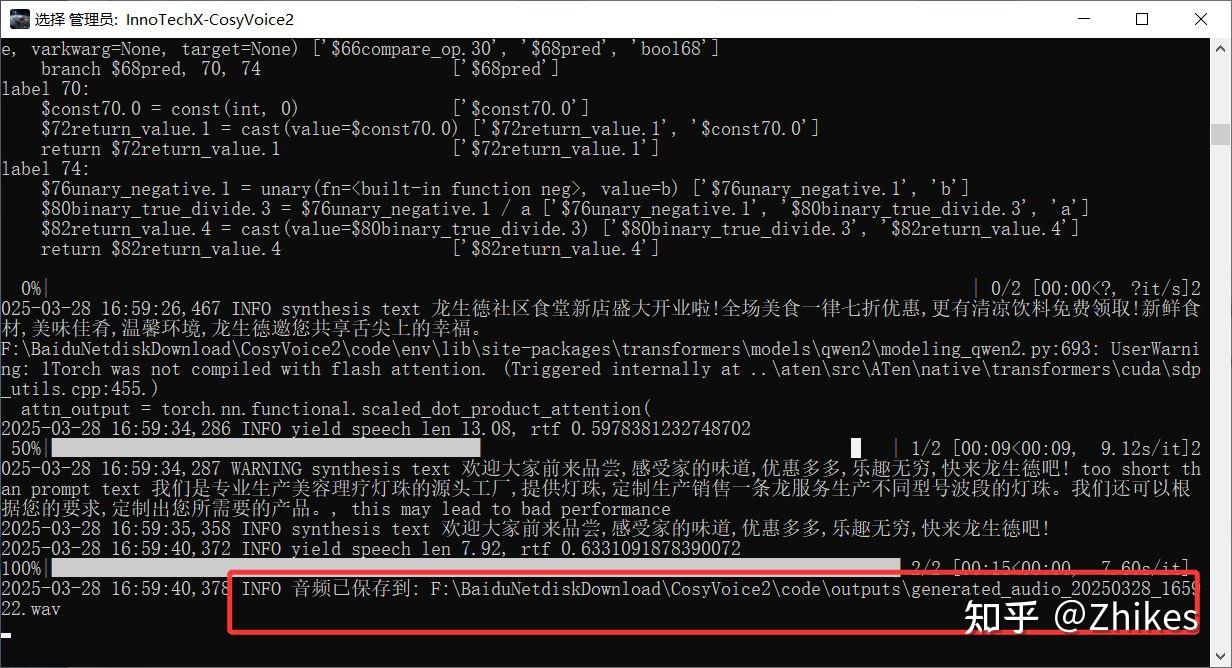
这一步的核心是生成一段与真人音色高度相似的文案音频,为后续的唇形同步打下基础。
第二步:唇形同步——让嘴型“动起来”
工具:LatentSync 一键包
获取方式:公众号,回复“ls”即可下载。
素材准备:
- 第一步生成的克隆文案音频。
- 一段真人朗读数字(如“12345…”)的视频。
操作流程:
- 打开 LatentSync 一键包,上传音频和视频。
- 点击运行,程序会自动分析音频并调整视频中的嘴型。
- 生成完视频,可以点击下载,拿到生成后的视频。
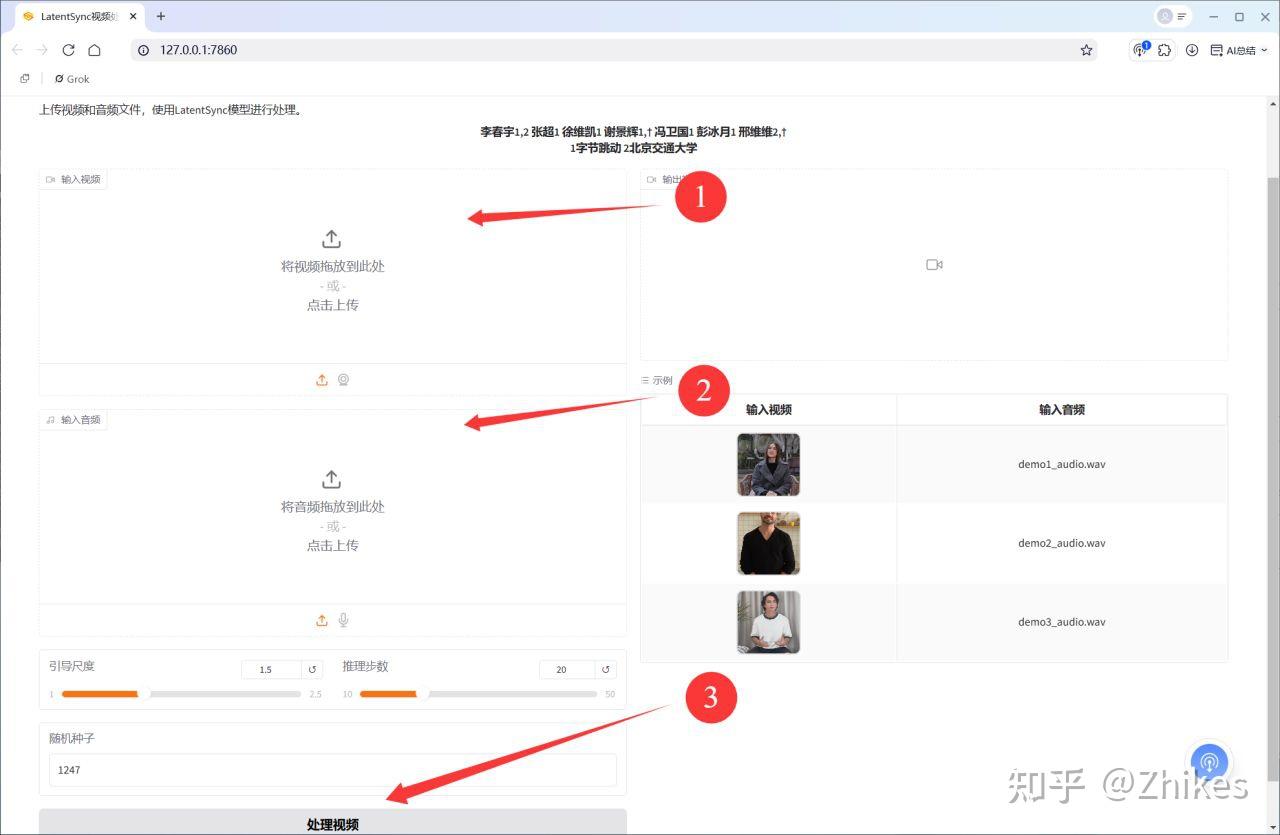
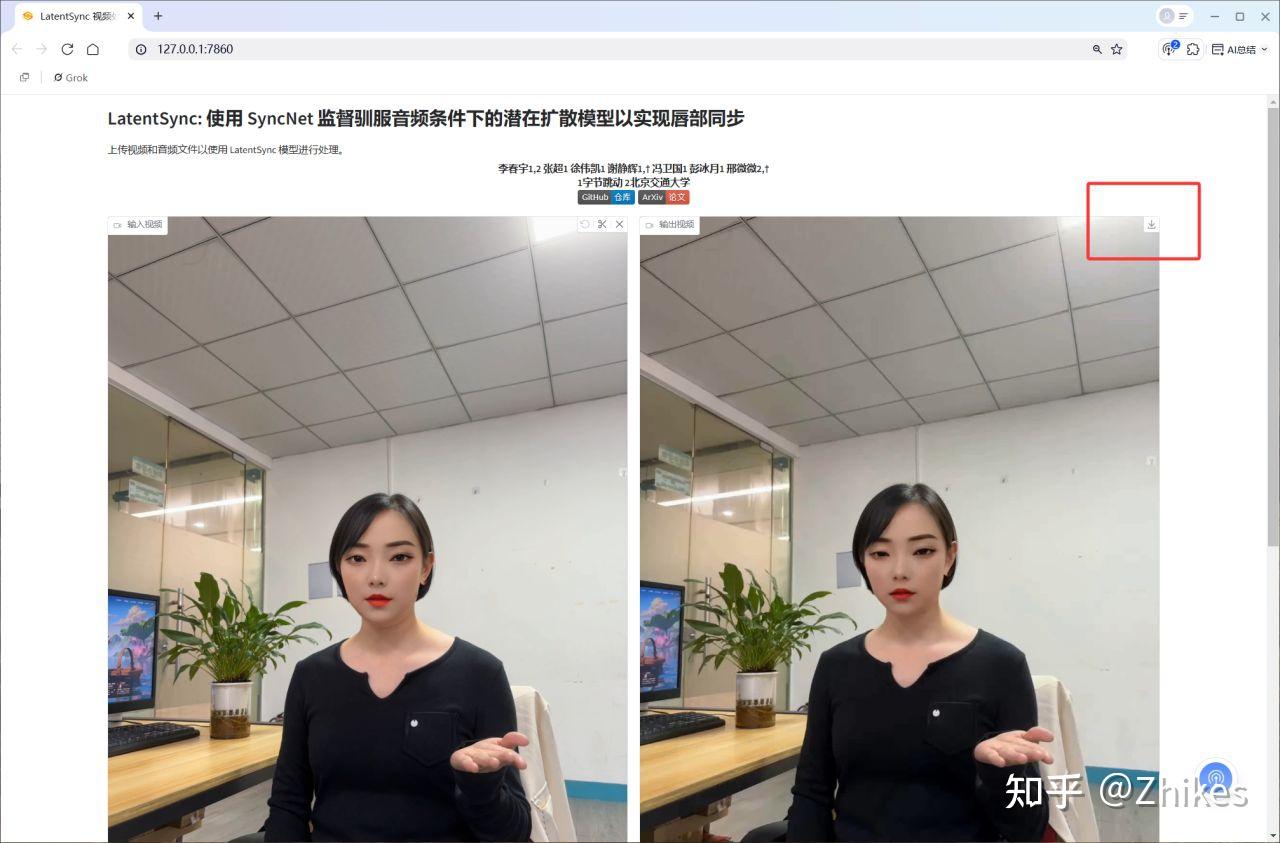
硬件要求:
LatentSync 对显卡有一定需求,建议使用配备 12~16GB 显存的英伟达显卡。如果你的电脑不符合条件,可以考虑云服务。本地部署和云算力教程在文末。
第三步:脸部高清增强——让画面“更逼真”
工具:FaceFusion
获取方式:公众号,回复“ff”即可下载。
操作流程:
- 打开 FaceFusion,进入程序界面。
- 在“处理器”选项中选择 face_enhancer(脸部增强功能 )
- 在“执行器”中选择 cuda,利用 GPU 加速处理。
- 目标文件上传第二步生成的视频(无需选择源文件)。
- 点击“开始”,等待处理完成。
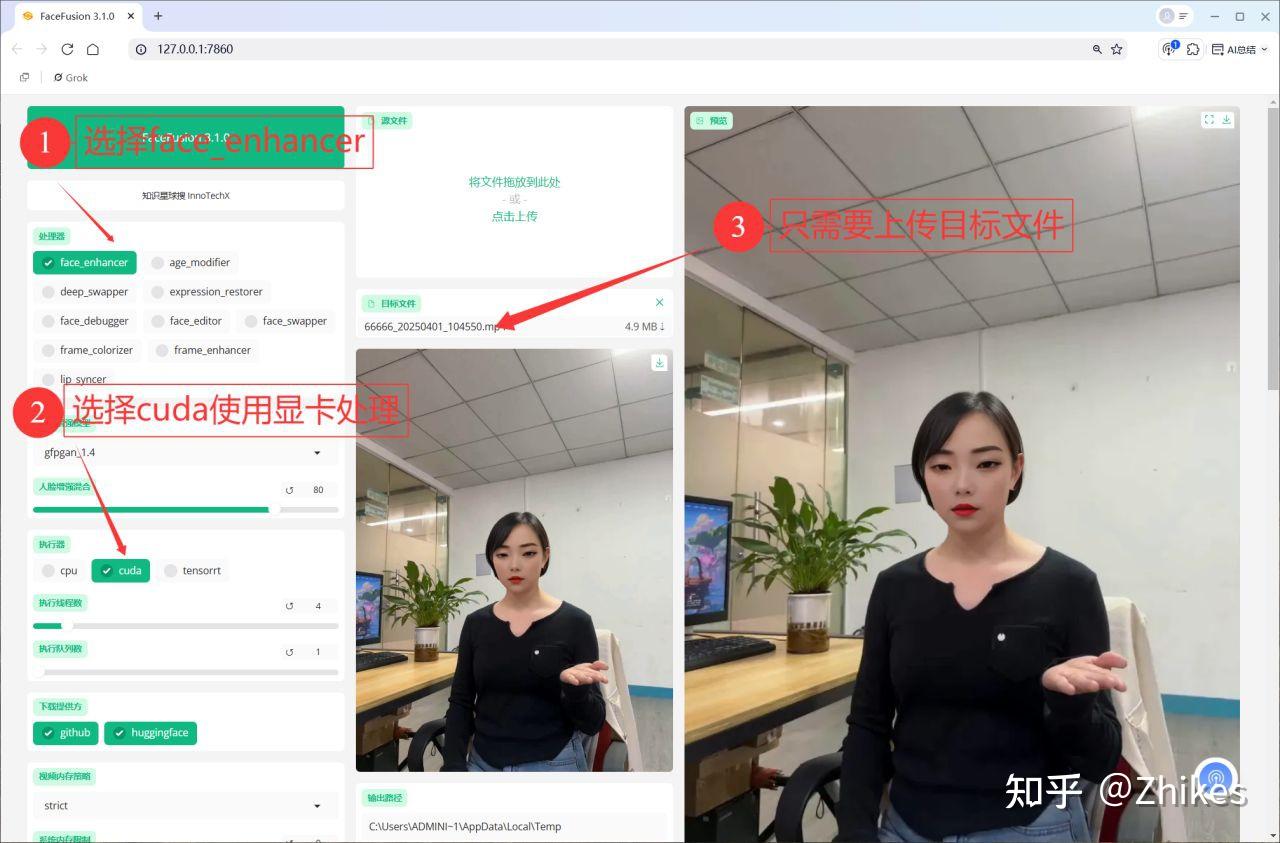
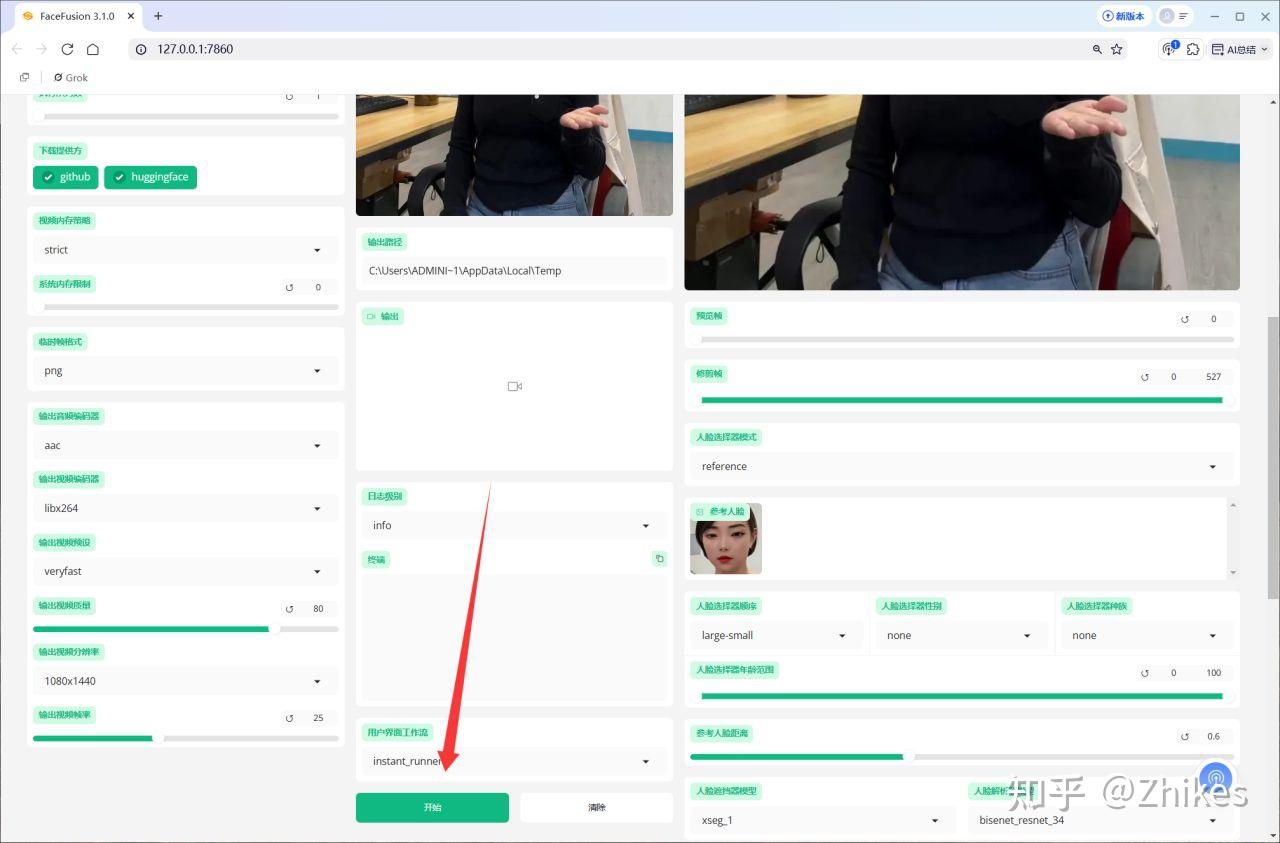
经过这一步,视频的清晰度会大幅提升,尤其是嘴巴周围的细节,看起来更加真实自然。我测试后发现,这种方法生成的效果甚至比外面使用3个月卖2000元的小程序还要出色。
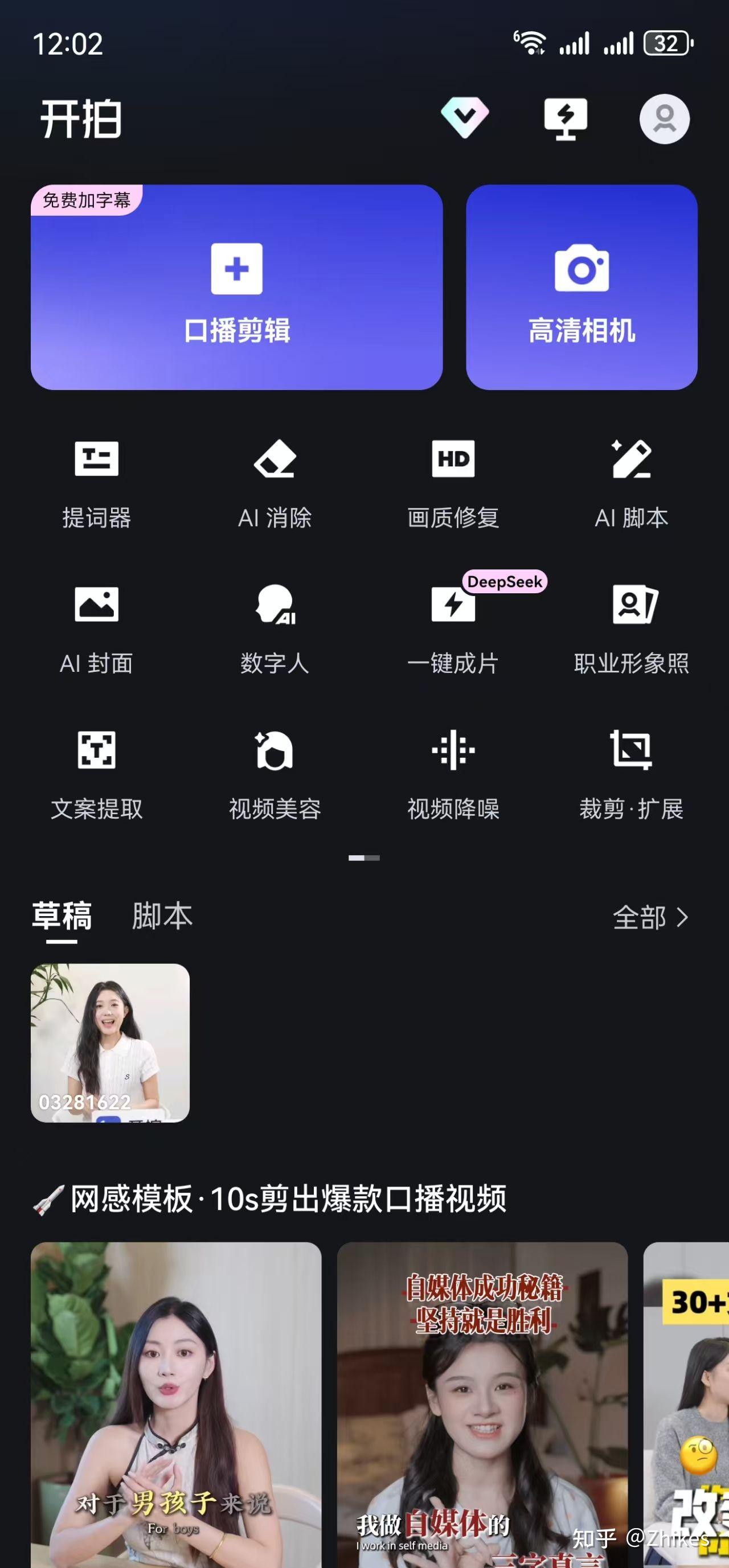
第四步:使用手机开拍软件,直接生成字幕和添加配背景音乐,加速视频编辑过程
进入软件选择口播剪辑
一键包装,选择模版
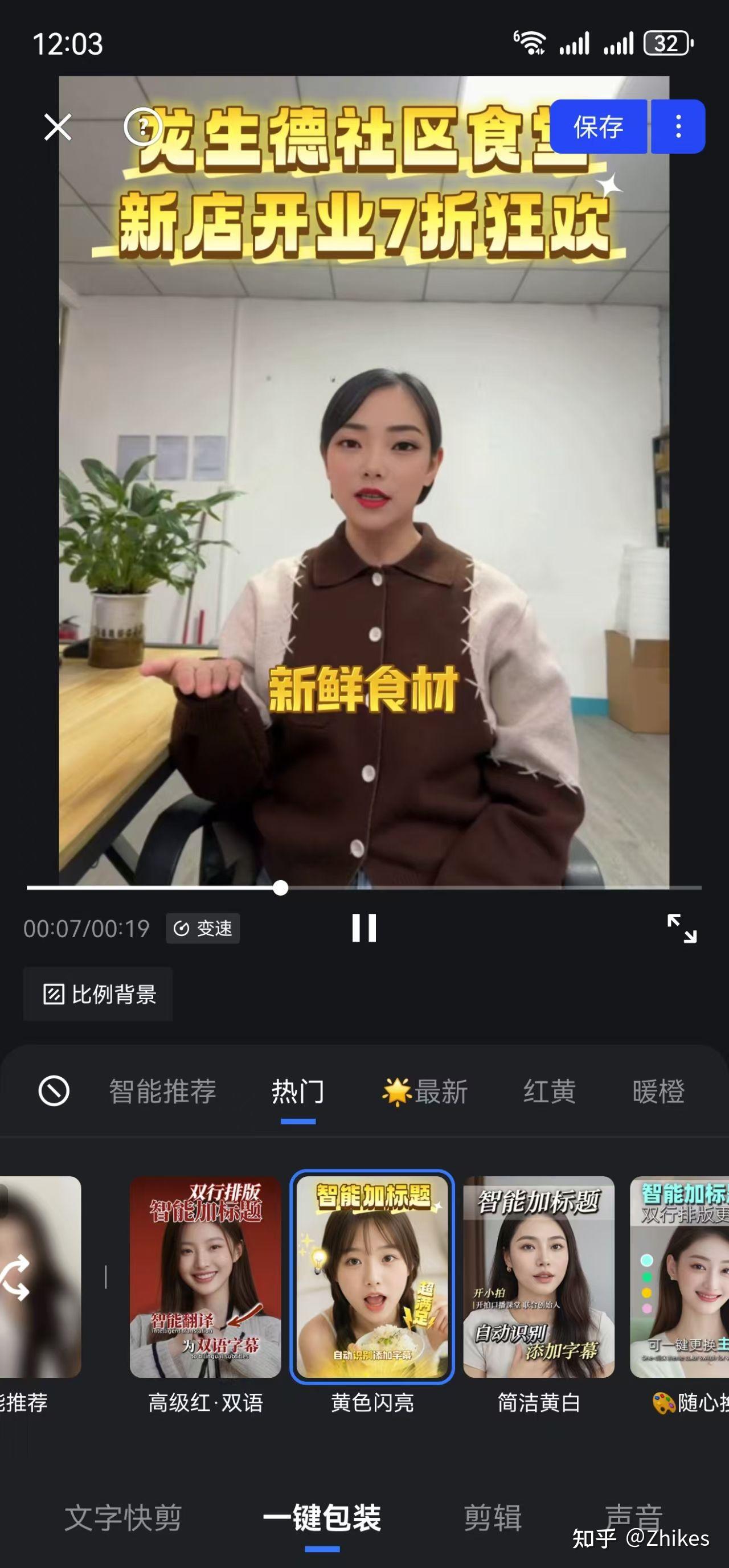
这样一套下来,很快就能完成一条视频的剪辑。
三、本地部署 LatentSync:技术爱好者的进阶选择
如果你对技术感兴趣,想完全掌控 lip-sync 视频的制作过程,可以尝试在本地部署 LatentSync,但是建议电脑的英伟达显卡最少12G显存再尝试本地部署,不然是运行不起来的。
你也可以选择云算力部署,依靠云算力,通过网页的方式,只需要两三分钟就能实现快速部署使用 LatentSync,下面放上我部署在云算力的镜像,可以直接部署 使用。
LatentSync镜像地址:https://www.xiangongyun.com/image/detail/a6943cd5-a17a-4698-879f-29e821d3d1b9
不知道云算力如何使用,可以参考这一篇文章https://mp.weixin.qq.com/s/kwzpFrIfR8F6i2kcr3rJvw
以下是本地部署简易指南:
环境准备:
- 安装 Miniconda(轻量级 Python 环境管理工具)。
- 安装 Git(版本控制工具)。
部署步骤:
- 克隆仓库:
- git clone https://github.com/bytedance/LatentSync cd LatentSync
- 创建虚拟环境:
- conda create -n LatentSync python=3.10
- conda activate LatentSync
- 安装 FFmpeg:
- conda install -y -c conda-forge ffmpeg
- 安装 Python 依赖:
- pip install -r requirements.txt
- pip install opencv-python opencv-contrib-python
- 下载模型文件:
- huggingface-cli download ByteDance/LatentSync-1.5 –local-dir checkpoints
- 启动 Gradio 界面:
- python gradio_app.py
完成后,你可以通过浏览器访问本地界面,上传音频和视频进行处理.
四、总结:技术在手,高价何求?
通过以上三个步骤,你可以用几乎零成本的方式制作出高质量的唇形同步视频。相比市面上动辄数千元的服务,这种方法不仅省钱,还能让你掌握核心技术,灵活应对各种需求。所有提到的工具(如 CosyVoice2、LatentSync 一键包、FaceFusion)在我的星球内都免费提供,欢迎加入交流!
后面考虑将这几个AI技术都融合起来,做一个支持批量的数字人工具供大家使用。
在 AI 技术飞速发展的今天,我们完全没必要为一些“包装精美”的服务掏空钱包。只要善用开源工具,稍微花点时间学习,你就能实现甚至超越那些高价项目的效果。希望这篇文章能帮你在 AI 数字人/唇形同步的探索中少走弯路,避免被“割韭菜”!
评论区